

Fundamentals of Reinforcement Learning
Uncover AI’s most exciting paradigm, underpinning today’s most exciting advancements – from DeepMind’s AlphaGo to OpenAI’s new O1 reasoning models.
This course provides a comprehensive overview of Reinforcement Learning fundamentals, approaching the main Markov Decision Process scenario via the simpler “k-armed bandits”.
The emphasis is on tabular methods (as opposed to “deep” RL), so that the focus is on the fundamental RL mechanisms.
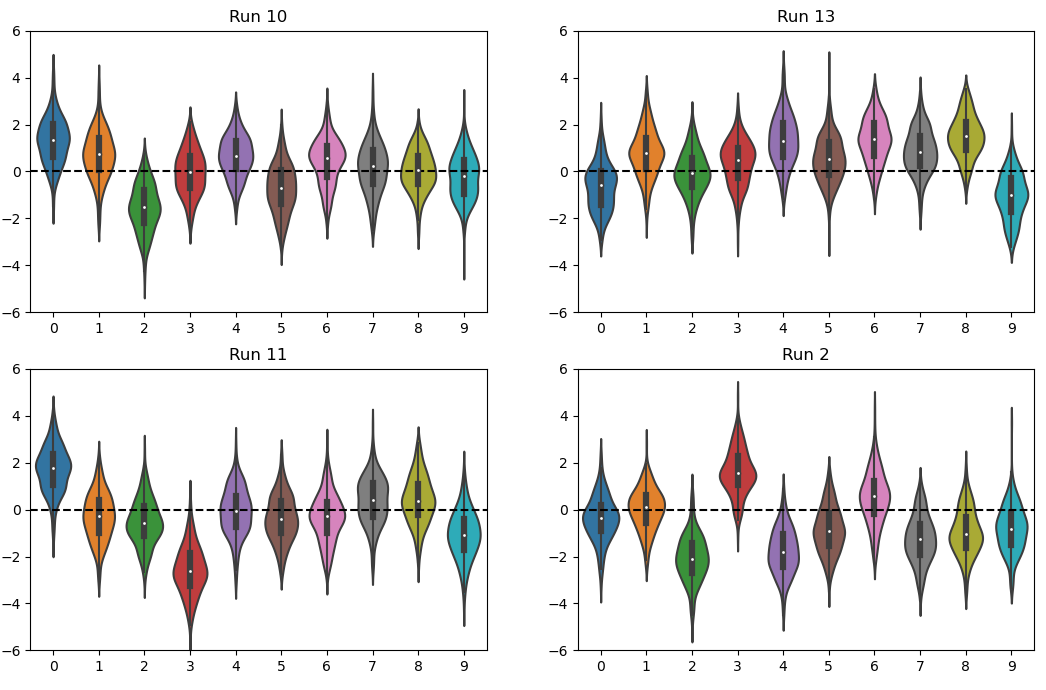
k-armed bandits
The k-armed bandit scenario builds towards the full RL setup, omitting the concepts of states and delayed rewards.
It nevertheless underpins many of the modern worlds applications, from social feed recommender systems to drug trial optimisation.
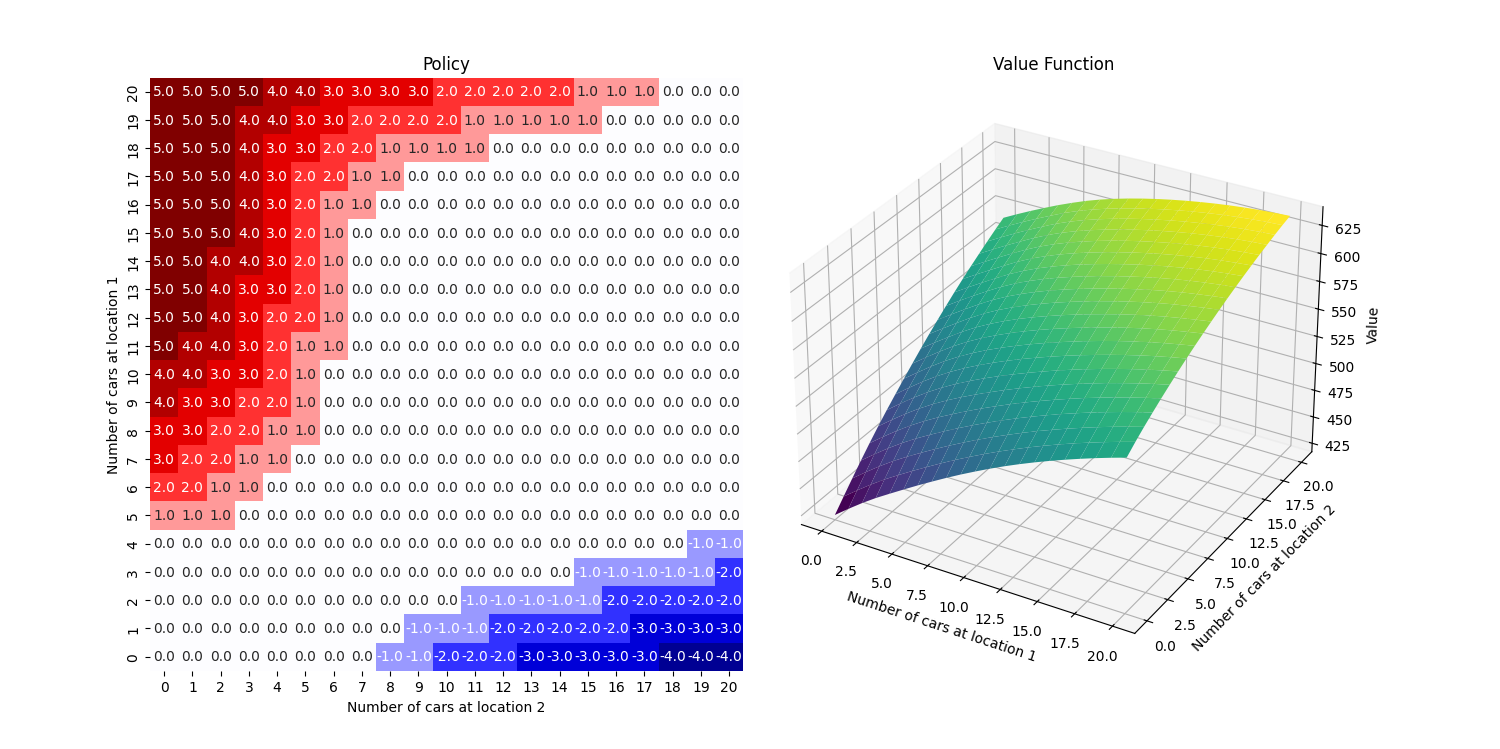
Markov Decision Processes (MDPs)
Markov Decision Processes form the framework that RL techniques aim to address.
In it, an agent seeks to maximise a “reward” signal over the long term, while interacting with an evolving and probabilistic environment.
The MDP formulation is incredibly flexible, and can describe setups as diverse as driverless cars, and tokomak fusion control to website optimisation.
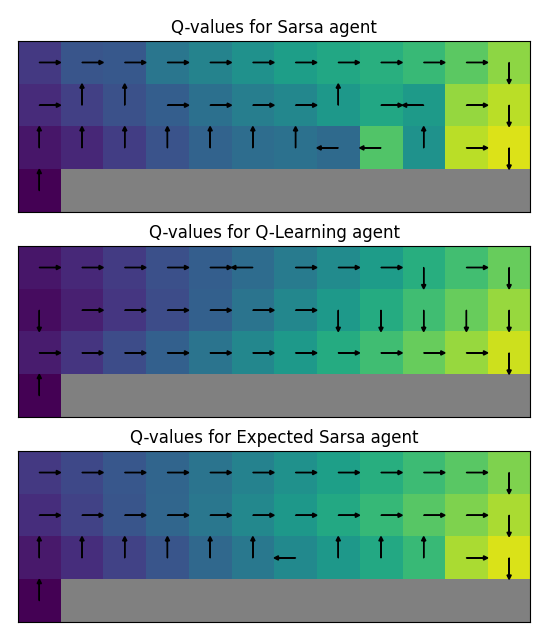
Reinforcement Learning (RL)
RL methods are learning-based algorithms which derive good action “policies” through experience with an environment within the MDP framework.
Through one of its founding fathers, Richard Bellman, the approach shares a common root with control engineering.
Where “good old-fashioned AI” (GOFAI) with hardcoded human expertise beat Garry Kasparov in Chess in the 90s, the learning approach of RL was required to master Go with DeepMind’s AlphaGo in the 2010s.
Today, the stage is set for RL to take on commercial realms typically the domain of GOFAI – engineering design, supply-chain optimisation and much more.
